

Schon 2017 erkannten wir das immense Potenzial von Künstlicher Intelligenz (KI) für unsere internen Prozesse und begannen, in Hardware zu investieren. Damals war leistbare und leistungsstarke AI-Hardware noch schwer zu finden, also bauten wir unsere eigenen Maschinen, um erste Experimente mit AI durchzuführen. Obwohl es uns an finanziellen Mitteln für das Training großer Sprachmodelle (LLMs) fehlte, konzentrierten wir uns darauf, die bestmögliche Hardware zu entwickeln, um in der AI-Welt mit Consumer-Hardware mitzuhalten.
Warum RTX 3090 für KI-Training?
Die NVIDIA RTX 3090, eine der stärksten Consumer-GPUs auf dem Markt, bietet mit 24 GB VRAM die nötige Speicherkapazität, um anspruchsvolle KI-Modelle zu laden und zu trainieren. In der Open-Source-Community hat sich gezeigt, dass diese GPUs für das Finetuning von großen Sprachmodellen (LLMs), TTS-Modellen und Bildgenerierungsmodellen hervorragend geeignet sind. Während Enterprise-GPUs wie die NVIDIA A100 oder H100 den Standard in Rechenzentren setzen, bieten unsere 3090er eine kostengünstige Alternative für ähnliche Aufgaben – bei einem Bruchteil der Kosten.
Erste Herausforderungen: Optimierung der Hardware
Als wir begannen, unsere Hardware für das KI-Training einzusetzen, stießen wir schnell auf technische Herausforderungen. Zwar war die Ausführung von Modellen auf unseren GPUs möglich, doch das Finetuning – insbesondere bei der Übertragung großer Datenmengen zwischen CPU-RAM und GPU-VRAM – erwies sich als anspruchsvoll. Die hohen Datenraten belasteten die Pipelines zwischen den Komponenten und führten zu Engpässen.
Der Deep Dive: Verbesserung der Hardware-Pipelines
Nach intensiver Analyse erkannten wir, dass die Engpässe in den PCIe-Schnittstellen und den CPU-RAM-Pipelines lagen. Um diese Flaschenhälse zu beseitigen, mussten wir unsere Hardware aufrüsten. Ein entscheidender Fortschritt war die Integration des ROME2D32GM-2T Motherboards, das zwei CPUs unterstützt. Diese Dual-CPU-Konfiguration ermöglicht eine bessere Verteilung der Rechenlast und optimiert den Datentransfer zwischen CPU und GPU. Mit SlimSAS-Verbindungen konnten wir eine direkte 8×8 PCIe-Verbindung zwischen den GPUs herstellen, was den Datendurchsatz maximiert und Latenz reduziert. Diese Architektur sorgt dafür, dass die GPUs effizient zusammenarbeiten, was gerade bei rechenintensiven Finetuning-Aufgaben entscheidend ist.
https://www.asrockrack.com/general/productdetail.asp?Model=ROME2D32GM-2T#Specifications
Moderne Tools und die Erweiterung unserer Kapazitäten
Dank der neuesten Entwicklungen in der KI-Software wie Ollama, LM Studio, vLLM oder OpenWebUI können wir die volle Leistung unserer GPUs ausschöpfen. Diese Tools erlauben es uns, die GPUs gleichzeitig zu nutzen, was es ermöglicht, selbst sehr große Modelle effizient zu laden und zu generieren. Wir haben erfolgreich Tests mit 6, 8, 10, 12 und sogar 16 GPUs auf einer einzigen Maschine durchgeführt. Somit bietet dies genug Leistung, um auch große Modelle mit bis zu 180 Milliarden Parametern problemlos zu laden und auszuführen.
Hier zwei Beispiel Bilder von zwei unsere Maschinen (6-GPUs und 10-GPUs):
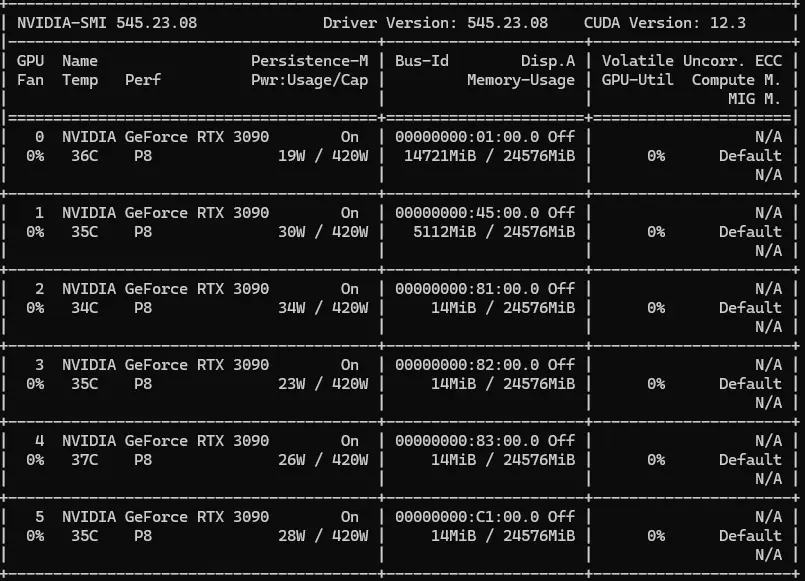
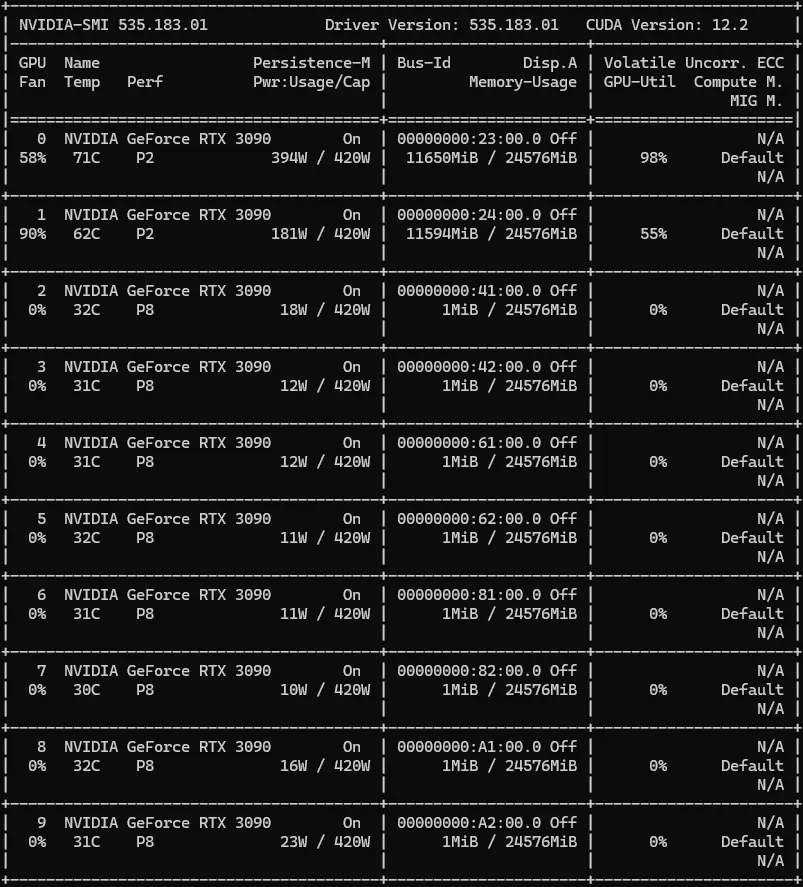
Ein besonderer Vorteil dieser Infrastruktur liegt in der Bildgenerierung und TTS-Technologien. Mit dieser Konfiguration können wir mehrere Bildgenerierungsmodelle wie ControlNets, Adapter oder VideoTools gleichzeitig laden und im Netzwerk abrufbereit anbieten. Dies erlaubt uns eine flexible und schnelle Bereitstellung von unterschiedlichen Modellen für kreative und industrielle Anwendungen.
Im Bereich TTS ermöglicht der große VRAM, mehrere Modelle gleichzeitig auf einer GPU zu laden. Dies beschleunigt das Testing von verschiedenen Trainingsschritten wie auch Parameter und erleichtert die Analyse der Ergebnisse. So können wir effizienter arbeiten und schneller auf neue Entwicklungen in der KI reagieren.
Fazit: Kosteneffiziente Hochleistung
Unsere Erfahrung zeigt, dass es möglich ist, mit sorgfältiger Planung und gezielten Hardware-Upgrades eine kosteneffiziente Lösung für das Training und Finetuning von KI-Modellen zu entwickeln. Mit unseren Custom Hardware Servern sind wir in der Lage, Aufgaben zu bewältigen, die sonst nur teuren Rechenzentren vorbehalten wären. Dies eröffnet nicht nur uns, sondern auch der Open-Source-Community neue Möglichkeiten, KI-Modelle effizient zu trainieren und anzupassen.
Unsere Reise vom Mining zur KI hat uns nicht nur gelehrt, wie wir Hardware optimal nutzen, sondern auch, wie wichtig es ist, flexibel auf neue Technologien und Anforderungen zu reagieren. Die Kombination aus leistungsstarker Hardware und modernen Tools ermöglicht es uns, die Grenzen dessen, was auf Consumer-Hardware möglich ist, immer weiter zu verschieben.